[python] pandas - iloc 예제
pandas 의 dataFrame에서 iloc 는 매우 자주 사용합니다. 처음 접하는 경우 생소하고 사용법이 익숙치 않아 내용을 알아둘 필요가 있습니다. 한걸음씩 우리 전진해 보자구요~

iloc에 대해 설명과 더불어 예시로 사용법을 알아보도록 하겠습니다.
iloc
iloc은 인덱스의 위치를 통해 데이터를 선택하는 인덱싱 방법 중 하나입니다. iloc은 "integer location"의 약자로, 정수 기반의 위치 인덱싱을 지원합니다.
iloc은 [] 연산자를 사용하여 데이터프레임의 특정 행과 열을 선택할 수 있습니다. iloc의 인자로는 행과 열을 선택하기 위한 정수 인덱스, 정수 범위, 또는 불리언 배열을 사용할 수 있습니다.
예를 들어, df.iloc[0:5, 0:3]은 데이터프레임에서 0번째부터 4번째까지(5는 포함되지 않음)의 행과 0번째부터 2번째까지(3은 포함되지 않음)의 열을 선택합니다.
iloc을 사용하면 데이터프레임에서 특정 행과 열을 선택할 수 있으며, 이를 통해 데이터프레임에서 원하는 부분을 추출하거나 수정할 수 있습니다. 또한 iloc을 사용하여 특정 조건을 만족하는 행이나 열을 선택하는 것도 가능합니다.
아래 예제에서 데이타 프레임은 df_temp로 정의했습니다.
df_temp.iloc[0:5, 0:3]
입력 데이터는 세 개의 열(A, B, C, D, E, F)과 각각 6개의 값을 가지고 있습니다.
import pandas as pd
import numpy as np
# 입력 데이터 생성
df_temp = pd.DataFrame(np.random.randint(0, 10, size=(6, 6)), columns=list('ABCDEF'))
# 입력 데이터 출력
print("Input data:")
print(df_temp)
# 0번째부터 4번째까지(5는 포함되지 않음)의 행과 0번째부터 2번째까지(3은 포함되지 않음)의 열 선택
df_temp_selected = df_temp.iloc[0:5, 0:3]
# 결과 출력
print("Result:")
print(df_temp_selected)
df_temp.iloc[0:5, 0:3]은 데이터프레임에서 0번째부터 4번째까지(5는 포함되지 않음)의 행과 0번째부터 2번째까지(3은 포함되지 않음)의 열을 선택한 결과입니다.
결과적으로 입력 데이터 중 0번째부터 4번째까지의 모든 행과 0번째부터 2번째까지의 모든 열이 선택된 데이터프레임이 출력됩니다.
Input data:
A B C D E F
0 5 6 5 8 8 4
1 4 9 4 4 4 4
2 4 2 7 2 2 9
3 8 1 3 7 3 8
4 3 6 3 3 3 6
5 5 6 5 1 5 6
Result:
A B C
0 5 6 5
1 4 9 4
2 4 2 7
3 8 1 3
4 3 6 3
df_temp.iloc[2:5, 1:3]
위와 동일한 코드에서 아래와 같이 수행했을 때는 어떤 결과가 나오는지 확인해 보겠습니다.
# 2번째부터 4번째까지(5는 포함되지 않음)의 행과 1번째부터 2번째까지(3은 포함되지 않음)의 열 선택
df_temp_selected = df_temp.iloc[2:5, 1:3]아래와 같은 결과가 출력됩니다.
Input data:
A B C D E F
0 7 3 3 3 8 4
1 1 7 6 4 9 4
2 4 8 4 6 1 7
3 2 1 9 4 4 8
4 7 2 2 2 8 7
5 3 7 3 6 3 3
Result:
B C
2 8 4
3 1 9
4 2 2
df_temp.iloc[:,:-1]
입력 데이터는 세 개의 열(col1, col2, col3)과 각각 3개의 값을 가지고 있습니다.
그리고 df_temp.iloc[:,:-1]은 마지막 열(col3)을 제외한 모든 열(col1, col2)을 선택한 결과입니다. 결과적으로 두 개의 열과 3개의 행으로 이루어진 데이터프레임이 출력됩니다.
import pandas as pd
# 입력 데이터 생성
df_temp = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [True, False, True]
})
# 입력 데이터 출력
print("Input data:")
print(df_temp)
# 마지막 열을 제외한 모든 열 선택
df_temp_except_last_column = df_temp.iloc[:,:-1]
# 결과 출력
print("Result:")
print(df_temp_except_last_column)
Input Data 와 Result 출력된 모습
Input data:
col1 col2 col3
0 1 a True
1 2 b False
2 3 c True
Result:
col1 col2
0 1 a
1 2 b
2 3 c
df.iloc[0]
단순히 숫자를 하나만 넣었을 때는 어떤 결과가 나오는지 궁금했습니다.
import pandas as pd
import numpy as np
# 입력 데이터 생성
df_temp = pd.DataFrame(np.random.randint(0, 10, size=(3, 3)), columns=list('ABC'))
# 입력 데이터 출력
print("Input data:")
print(df_temp)
# 첫 번째 행 선택
df_temp_selected = df_temp.iloc[0]
# 결과 출력
print("Result:")
print(df_temp_selected)첫번째 컬럼의 데이타만 선택되었음을 알 수 있습니다.
Input data:
A B C
0 3 5 7
1 3 7 5
2 7 5 9
Result:
A 3
B 5
C 7
Name: 0, dtype: int32
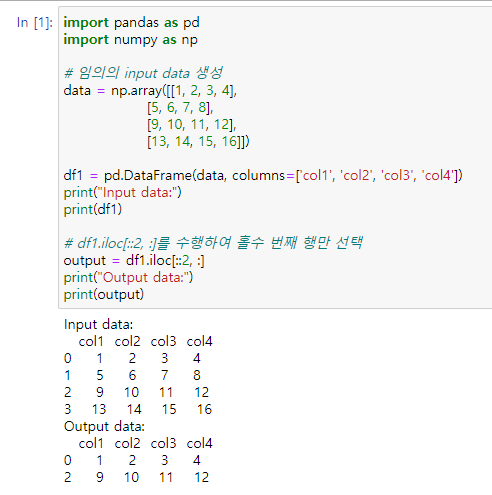
iloc[::2, :]
iloc[::2, :]는 df1의 모든 열을 가져오되, 행은 0부터 시작하여 2씩 건너뛰어서 선택하라는 의미입니다. 이러한 인덱싱 방법은 슬라이싱(slicing)을 사용하여 구현됩니다. 따라서 첫 번째 콜론(:)은 열의 선택을 의미하고, 두 번째 콜론(:)은 모든 열을 선택하라는 의미입니다.
즉, iloc[::2, :]는 df1의 0번째, 2번째, 4번째 등의 짝수 행에 해당하는 데이터만 선택하여 반환합니다.
import pandas as pd
import numpy as np
# 임의의 input data 생성
data = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]])
df1 = pd.DataFrame(data, columns=['col1', 'col2', 'col3', 'col4'])
print("Input data:")
print(df1)
# df1.iloc[::2, :]를 수행하여 홀수 번째 행만 선택
output = df1.iloc[::2, :]
print("Output data:")
print(output)Input data:
col1 col2 col3 col4
0 1 2 3 4
1 5 6 7 8
2 9 10 11 12
3 13 14 15 16
Output data:
col1 col2 col3 col4
0 1 2 3 4
2 9 10 11 12
실제 코드를 수행해서 나온 결과
댓글