Bash shell script : cut 사용법
업무 중에 c++, python 등으로 코드를 개발해 돌려볼 수도 있지만, 간단하게 shell script를 활용하는 방향이 가장 빠른 경우가 있습니다. Linux 시스템에서는 아무래도 shell script로 간단하게 일을 처리해 원하는 결과를 얻는 방향이 좋습니다.
기본만 제대로 알아도 shell script 만드는 데 큰 문제가 없습니다. 그 기본 명령어 중에서 cut 정보를 아래 정리해 담았습니다.
cut
cut 은 구분자로 구분하여 원하는 값을 얻어낼 수 있는 linux 기본 명령어 입니다.
cut 주요 옵션 및 내용
| -c | 지정한 행을 출력 |
| -d | 딜리미터를 지정 |
| -f | 딜리미터로 잘라진 행을 출력 |
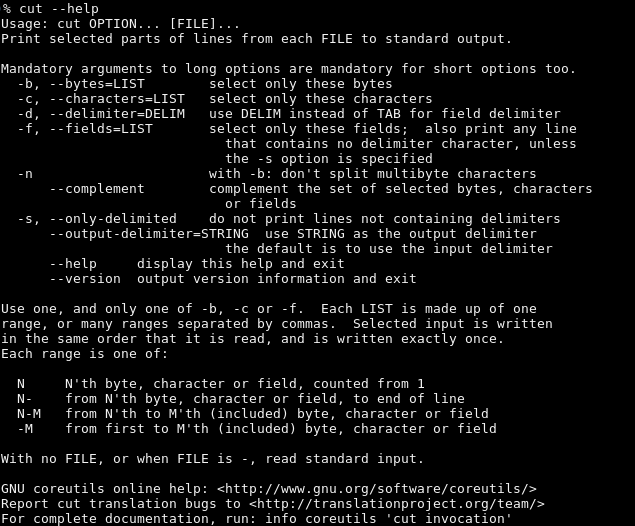
* 모든 답은 help에 있습니다. cut --help 로 확인할 수 있습니다.
기본 예제
$ echo "ABCDE" | cut -c 1
A
$ echo "ABCDE" | cut -c 2
B
$ echo "ABCDE" | cut -c 3
C
$ echo "ABCDE" | cut -c 2-3
BC
$ echo "A,B,C,D,E" | cut -d"," -f 2
B
$ echo "A:B:C:D:E" | cut -d":" -f 3
C
Bash shell script에서 실제 사용하는 방법
input data :
- 데이타 파일(input_file)의 구분자(-d)가 콤마(,) 로 구분되어 있습니다.
- 가장 첫번째 데이타를 -f 옵션으로 가져와 리스트로 만들고 싶습니다.

output :
- 가장 첫번째 데이타들 (2 3 2 2 3 3 3 1 1 1 1)에서 중복을 제거한 값들을 리스트로 만들고 싶습니다.

shell script :
- 아래의 예제에서는 echo 로 line의 값을 cut을 활용해 구분자를 지정해 값을 뽑아낼 수 있습니다.
- 사이즈가 정해지지 않은 배열 선언 방법으로 배열을 선언합니다.
- 카운트(count) 값을 정의해 배열에 값을 저장할 때 사용합니다.
- while 문을 사용해 파일의 모든 line을 읽어옵니다.
- 읽어온 값이 숫자인 경우에만 처리하고 숫자가 아니면 continue로 다음 라인을 읽습니다.
- 배열의 중복을 제거한 리스트를 생성하고 출력합니다.
#!/bin/bash
input_file=$1 # shell 입력 인자가 input_file
count=0
## 사이즈가 정해지지 않은 배열 data_list를 선언함
declare -a data_list
while IFS= read -r line #파일 한줄씩 읽어서 line에 담기
do
### cut 명령어로 구분자(-d)를 , 로 구분해서 구분지어진 첫번째 값을 가져옴
data=$(echo $line | cut -d"," -f 1)
### data 값이 숫자인 경우에만 처리됨
RET=${data//[0-9]/}
if [ -n "$RET" ]; then
continue
fi
### data 값을 data_list (배열)에 저장하기 data_list[count] 형태로 저장됨
data_list[$count]=$data
### count 값을 하나 증가시킴
let "count+=1"
done < $input_file #while문에서 input_file을 처리함
### 배열의 중복을 제거해 result list를 생성
result=`echo "${cell_list[@]}" | tr ' ' '\n' | sort -u | tr '\n' ' '`
echo $result

당신에게 유용한 정보
'shell' 카테고리의 다른 글
| [Linux] bash : date 명령어 사용 방법 (0) | 2021.07.30 |
|---|

댓글